Hinweis
Gehen Sie zum Ende, um den vollständigen Beispielcode herunterzuladen.
Asinh-Skala#
Illustration der asinh-Achsenskalierung, die die Transformation verwendet
Für Koordinatenwerte nahe Null (d. h. viel kleiner als die "lineare Breite" \(a_0\)) bleiben die Werte im Wesentlichen unverändert
aber für größere Werte (d. h. \(|a| \gg a_0\)) ist dies asymptotisch
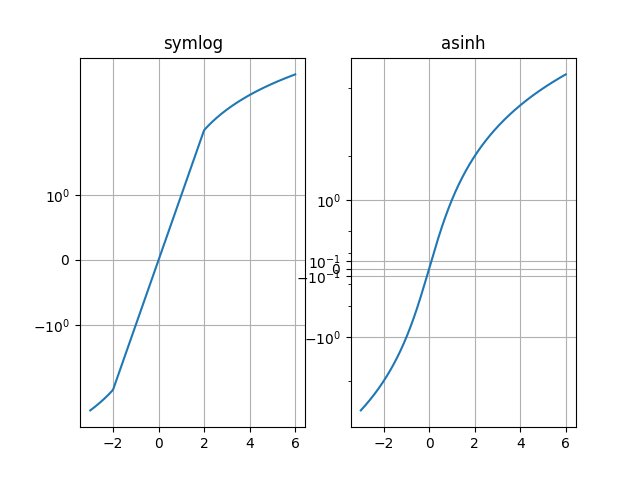
Wie bei der symlog-Skalierung ermöglicht dies die Darstellung von Größen, die einen sehr großen dynamischen Bereich abdecken, der sowohl positive als auch negative Werte enthält. Allerdings verwendet symlog eine Transformation, die aufgrund der Tatsache, dass sie aus *separaten* linearen und logarithmischen Transformationen aufgebaut ist, Diskontinuitäten in ihrem Gradienten aufweist. Die asinh-Skalierung verwendet eine Transformation, die für alle (endlichen) Werte glatt ist, was sowohl mathematisch sauberer ist als auch visuelle Artefakte reduziert, die mit einem abrupten Übergang zwischen linearen und logarithmischen Bereichen des Plots verbunden sind.
Hinweis
scale.AsinhScale ist experimentell und die API kann sich ändern.
Siehe AsinhScale, SymmetricalLogScale.
import matplotlib.pyplot as plt
import numpy as np
# Prepare sample values for variations on y=x graph:
x = np.linspace(-3, 6, 500)
Vergleiche "symlog" und "asinh" Verhalten auf einem Beispiel y=x Graphen, wo es einen diskontinuierlichen Gradienten in "symlog" nahe y=2 gibt
fig1 = plt.figure()
ax0, ax1 = fig1.subplots(1, 2, sharex=True)
ax0.plot(x, x)
ax0.set_yscale('symlog')
ax0.grid()
ax0.set_title('symlog')
ax1.plot(x, x)
ax1.set_yscale('asinh')
ax1.grid()
ax1.set_title('asinh')
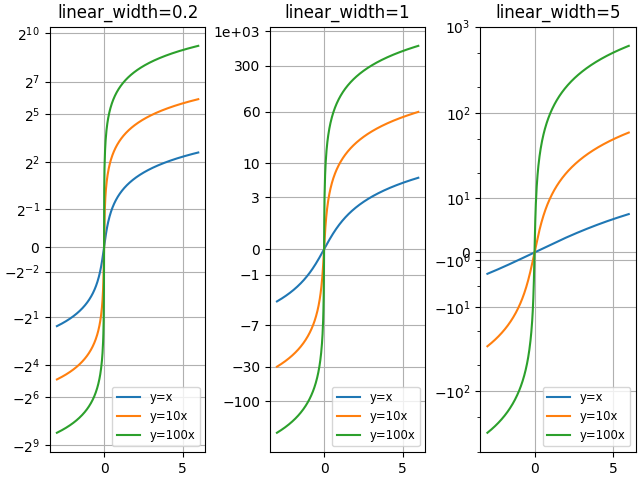
Vergleiche "asinh" Graphen mit unterschiedlichem Skalenparameter "linear_width"
fig2 = plt.figure(layout='constrained')
axs = fig2.subplots(1, 3, sharex=True)
for ax, (a0, base) in zip(axs, ((0.2, 2), (1.0, 0), (5.0, 10))):
ax.set_title(f'linear_width={a0:.3g}')
ax.plot(x, x, label='y=x')
ax.plot(x, 10*x, label='y=10x')
ax.plot(x, 100*x, label='y=100x')
ax.set_yscale('asinh', linear_width=a0, base=base)
ax.grid()
ax.legend(loc='best', fontsize='small')
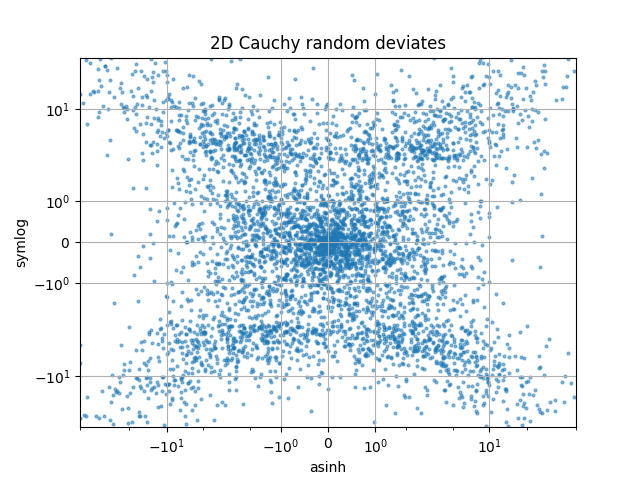
Vergleiche "symlog" und "asinh" Skalierungen auf 2D Cauchy-verteilten Zufallszahlen, wo man aufgrund der Gradienten-Diskontinuität in "symlog" subtilere Artefakte nahe y=2 erkennen kann
fig3 = plt.figure()
ax = fig3.subplots(1, 1)
r = 3 * np.tan(np.random.uniform(-np.pi / 2.02, np.pi / 2.02,
size=(5000,)))
th = np.random.uniform(0, 2*np.pi, size=r.shape)
ax.scatter(r * np.cos(th), r * np.sin(th), s=4, alpha=0.5)
ax.set_xscale('asinh')
ax.set_yscale('symlog')
ax.set_xlabel('asinh')
ax.set_ylabel('symlog')
ax.set_title('2D Cauchy random deviates')
ax.set_xlim(-50, 50)
ax.set_ylim(-50, 50)
ax.grid()
plt.show()
Referenzen
Gesamtlaufzeit des Skripts: (0 Minuten 2,584 Sekunden)