matplotlib.pyplot.hist#
- matplotlib.pyplot.hist(x, bins=None, *, range=None, density=False, weights=None, cumulative=False, bottom=None, histtype='bar', align='mid', orientation='vertical', rwidth=None, log=False, color=None, label=None, stacked=False, data=None, **kwargs)[Quelle]#
Berechnet und plottet ein Histogramm.
Diese Methode verwendet
numpy.histogram, um die Daten in x zu klassifizieren und die Anzahl der Werte in jeder Klasse zu zählen. Anschließend wird die Verteilung entweder alsBarContaineroderPolygongezeichnet. Die Parameter bins, range, density und weights werden annumpy.histogramweitergeleitet.Wenn die Daten bereits klassifiziert und gezählt wurden, verwenden Sie
baroderstairs, um die Verteilung zu zeichnen.counts, bins = np.histogram(x) plt.stairs(counts, bins)
Alternativ können Sie vorab berechnete Klassen und Zählungen mit
hist()plotten, indem Sie jede Klasse als einzelnen Punkt mit einem Gewicht behandeln, das seiner Zählung entspricht.plt.hist(bins[:-1], bins, weights=counts)
Die Eingabe x kann ein einzelnes Array, eine Liste von Datensätzen potenziell unterschiedlicher Längen ([x0, x1, ...]) oder ein 2D-ndarray sein, bei dem jede Spalte ein Datensatz ist. Beachten Sie, dass die ndarray-Form transponiert im Vergleich zur Listenform ist. Wenn die Eingabe ein Array ist, ist der Rückgabewert ein Tupel (n, bins, patches); wenn die Eingabe eine Sequenz von Arrays ist, ist der Rückgabewert ein Tupel ([n0, n1, ...], bins, [patches0, patches1, ...]).
Maskierte Arrays werden nicht unterstützt.
- Parameter:
- x(n,) Array oder Sequenz von (n,) Arrays
Eingabewerte, dies kann entweder ein einzelnes Array oder eine Sequenz von Arrays sein, die nicht die gleiche Länge haben müssen.
- binsint oder Sequenz oder str, Standard:
rcParams["hist.bins"](Standard:10) Wenn bins eine ganze Zahl ist, definiert sie die Anzahl der gleichbreiten Klassen im Bereich.
Wenn bins eine Sequenz ist, definiert sie die Klassengrenzen, einschließlich der linken Grenze der ersten Klasse und der rechten Grenze der letzten Klasse; in diesem Fall können die Klassen ungleich beabstandet sein. Alle außer der letzten (rechtesten) Klasse sind halboffen. Das heißt, wenn bins
[1, 2, 3, 4]
dann ist die erste Klasse
[1, 2)(einschließlich 1, aber ausschließend 2) und die zweite[2, 3). Die letzte Klasse ist jedoch[3, 4], die 4 *einschließt*.Wenn bins ein String ist, ist es eine der von
numpy.histogram_bin_edgesunterstützten Klassifizierungsstrategien: 'auto', 'fd', 'doane', 'scott', 'stone', 'rice', 'sturges' oder 'sqrt'.- rangeTupel oder None, Standard: None
Der untere und obere Bereich der Klassen. Ausreißer nach unten und oben werden ignoriert. Wenn nicht angegeben, ist range
(x.min(), x.max()). Der Bereich hat keine Auswirkung, wenn bins eine Sequenz ist.Wenn bins eine Sequenz ist oder range angegeben ist, basiert die automatische Skalierung auf dem angegebenen Klassengrenzwert anstelle des Bereichs von x.
- densitybool, Standard: False
Wenn
True, zeichne und gib eine Wahrscheinlichkeitsdichte zurück: Jede Klasse zeigt die rohe Anzahl der Klasse geteilt durch die Gesamtzahl der Zählungen *und die Klassenbreite* (density = counts / (sum(counts) * np.diff(bins))) an, sodass die Fläche unter dem Histogramm zu 1 integriert (np.sum(density * np.diff(bins)) == 1).Wenn stacked ebenfalls
Trueist, wird die Summe der Histogramme auf 1 normiert.- weights(n,) Array-ähnlich oder None, Standard: None
Ein Array von Gewichten mit der gleichen Form wie x. Jeder Wert in x trägt nur sein zugehöriges Gewicht zur Klassenzählung bei (statt 1). Wenn density
Trueist, werden die Gewichte normiert, sodass das Integral der Dichte über den Bereich 1 bleibt.- cumulativebool oder -1, Standard: False
Wenn
True, wird ein Histogramm berechnet, bei dem jede Klasse die Zählungen in dieser Klasse und allen Klassen für kleinere Werte angibt. Die letzte Klasse gibt die Gesamtzahl der Datenpunkte an.Wenn density ebenfalls
Trueist, wird das Histogramm so normiert, dass die letzte Klasse 1 ergibt.Wenn cumulative eine Zahl kleiner als 0 ist (z. B. -1), wird die Richtung der Akkumulation umgekehrt. In diesem Fall, wenn density ebenfalls
Trueist, wird das Histogramm so normiert, dass die erste Klasse 1 ergibt.- bottomArray-ähnlich oder float, Standard: 0
Position der Unterseite jeder Klasse, d.h. Klassen werden von
bottombisbottom + hist(x, bins)gezeichnet. Wenn ein Skalar, wird die Unterseite jeder Klasse um denselben Betrag verschoben. Wenn ein Array, wird jede Klasse unabhängig verschoben und die Länge von bottom muss mit der Anzahl der Klassen übereinstimmen. Wenn None, ist der Standardwert 0.- histtype{'bar', 'barstacked', 'step', 'stepfilled'}, Standard: 'bar'
Der Typ des zu zeichnenden Histogramms.
'bar' ist ein traditionelles Histogramm vom Balkentyp. Wenn mehrere Daten gegeben sind, werden die Balken nebeneinander angeordnet.
'barstacked' ist ein Histogramm vom Balkentyp, bei dem mehrere Daten übereinander gestapelt werden.
'step' erzeugt einen Linienplot, der standardmäßig ungefüllt ist.
'stepfilled' erzeugt einen Linienplot, der standardmäßig gefüllt ist.
- align{'left', 'mid', 'right'}, Standard: 'mid'
Die horizontale Ausrichtung der Histogrammbalken.
'left': Balken werden auf den linken Klassengrenzen zentriert.
'mid': Balken werden zwischen den Klassengrenzen zentriert.
'right': Balken werden auf den rechten Klassengrenzen zentriert.
- orientation{'vertical', 'horizontal'}, Standard: 'vertical'
Wenn 'horizontal', wird
barhfür Balken-Histogramme verwendet und das bottom-Schlüsselwortargument sind die linken Grenzen.- rwidthfloat oder None, Standard: None
Die relative Breite der Balken als Bruchteil der Klassenbreite. Wenn
None, wird die Breite automatisch berechnet.Ignoriert, wenn histtype 'step' oder 'stepfilled' ist.
- logbool, Standard: False
Wenn
True, wird die Histogrammachse auf eine logarithmische Skala gesetzt.- colorFarbe oder Liste von Farben oder None, Standard: None
Farbe oder Sequenz von Farben, eine pro Datensatz. Standard (
None) verwendet die Standard-Linienfarbsequenz.- labelstr oder Liste von str, optional
String oder Sequenz von Strings zur Übereinstimmung mehrerer Datensätze. Balkendiagramme erzeugen mehrere Patches pro Datensatz, aber nur der erste erhält das Label, damit
legendwie erwartet funktioniert.- stackedbool, Standard: False
Wenn
True, werden mehrere Daten übereinander gestapelt. WennFalse, werden mehrere Daten nebeneinander angeordnet, wenn histtype 'bar' ist, oder übereinander, wenn histtype 'step' ist.
- Gibt zurück:
- nArray oder Liste von Arrays
Die Werte der Histogrammklassen. Siehe density und weights für eine Beschreibung der möglichen Semantiken. Wenn die Eingabe x ein Array ist, dann ist dies ein Array der Länge nbins. Wenn die Eingabe eine Sequenz von Arrays
[data1, data2, ...]ist, dann ist dies eine Liste von Arrays mit den Werten der Histogramme für jedes der Arrays in der gleichen Reihenfolge. Der Datentyp des Arrays n (oder seiner Element-Arrays) ist immer float, auch wenn keine Gewichtung oder Normalisierung verwendet wird.- binsArray
Die Ränder der Klassen. Länge nbins + 1 (nbins linke Ränder und rechter Rand der letzten Klasse). Immer ein einzelnes Array, auch wenn mehrere Datensätze übergeben werden.
- patches
BarContaineroder Liste eines einzelnenPolygonoder Liste solcher Objekte Container von einzelnen Künstlern, die zur Erstellung des Histogramms verwendet werden, oder Liste solcher Container, wenn mehrere Eingabedatensätze vorhanden sind.
- Andere Parameter:
- dataindizierbares Objekt, optional
Wenn angegeben, akzeptieren die folgenden Parameter auch einen String
s, der alsdata[s]interpretiert wird, wennsein Schlüssel indataistx, weights
- **kwargs
Patch-Eigenschaften. Die folgenden Eigenschaften akzeptieren zusätzlich eine Sequenz von Werten, die den Datensätzen in x entsprechen: edgecolor, facecolor, linewidth, linestyle, hatch.Hinzugefügt in Version 3.10: Ermöglicht Sequenzen von Werten in den oben aufgeführten Patch-Eigenschaften.
Siehe auch
Anmerkungen
Hinweis
Dies ist der pyplot-Wrapper für
axes.Axes.hist.Bei einer großen Anzahl von Klassen (>1000) kann das Plotten durch die Verwendung von
stairszum Plotten eines vorab berechneten Histogramms (plt.stairs(*np.histogram(data))) oder durch Setzen von histtype auf 'step' oder 'stepfilled' anstelle von 'bar' oder 'barstacked' erheblich beschleunigt werden.
Beispiele, die matplotlib.pyplot.hist verwenden#
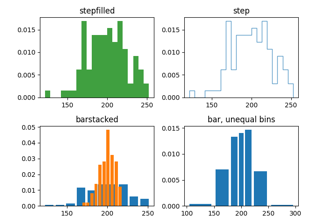
Demo der verschiedenen histtype-Einstellungen der Histogrammfunktion
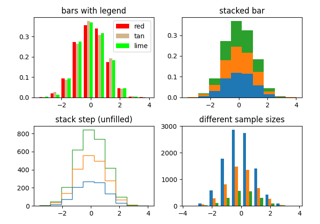
Die Histogrammfunktion (hist) mit mehreren Datensätzen