DievizAPI
viz API Referenz¶
-
probscale.viz.probplot(data, ax=None, plottype='prob', dist=None, probax='x', problabel=None, datascale='linear', datalabel=None, bestfit=False, return_best_fit_results=False, estimate_ci=False, ci_kws=None, pp_kws=None, scatter_kws=None, line_kws=None, **fgkwargs)[Quelle]¶ Wahrscheinlichkeits-, Perzentil- und Quantilplots.
Parameter data : array-ähnlich
1-dimensionale Daten, die geplottet werden sollen
ax : matplotlib axes, optional
Die Achsen, auf denen geplottet werden soll. Wenn keine angegeben ist, wird eine neue Achse erstellt.
plottype : string (Standard = 'prob')
Art des zu erstellenden Plots. Optionen sind
- 'prob': Wahrscheinlichkeitsplot
- 'pp': Perzentilplot
- 'qq': Quantilplot
dist : scipy Verteilung, optional
Eine Verteilung zur Berechnung der Skalen-Tickpositionen. Wenn nicht angegeben, wird eine Standard-Normalverteilung verwendet.
probax : string, optional (Standard = 'x')
Die Achse ('x' oder 'y'), die als Wahrscheinlichkeits- (oder Quantil-) Achse dient.
problabel, datalabel : string, optional
Achsenbeschriftungen für die Wahrscheinlichkeits-/Quantil- und Datenachsen.
datascale : string, optional (Standard = 'log')
Skala für die andere Achse, die nicht
bestfit : bool, optional (Standard ist False)
Gibt an, ob eine "Best-Fit"-Linie zum Plot hinzugefügt werden soll.
return_best_fit_results : bool (Standard ist False)
Wenn True, wird ein Dictionary mit den Ergebnissen zusammen mit der Abbildung zurückgegeben.
estimate_ci : bool, optional (False)
Schätzt und zeichnet ein Konfidenzband um die "Best-Fit"-Linie mittels eines Perzentil-Bootstraps.
ci_kws : dict, optional
Dictionary von Schlüsselwortargumenten, die direkt an
viz.fit_lineübergeben werden, wenn die "Best-Fit"-Linie berechnet wird.pp_kws : dict, optional
Dictionary von Schlüsselwortargumenten, die direkt an
viz.plot_posübergeben werden, wenn die Plotting-Positionen berechnet werden.scatter_kws, line_kws : dict, optional
Dictionary von Schlüsselwortargumenten, die direkt an
ax.plotübergeben werden, wenn die Scatter-Punkte und die "Best-Fit"-Linie gezeichnet werden.Rückgabe fig : matplotlib.Figure
Die Abbildung, auf der der Plot gezeichnet wurde.
result : dict von linearen Fit-Ergebnissen, optional
Schlüssel sind
- q : Array von Quantilen
- x, y : Arrays der an die Funktion übergebenen Daten
- xhat, yhat : Arrays von modellierten Daten, die in der "Best-Fit"-Linie geplottet wurden
- res : Array von Koeffizienten der "Best-Fit"-Linie.
Andere Parameter color : string, optional
Ein direkt angegebener matplotlib-Farbargument für sowohl die Datenserie als auch die "Best-Fit"-Linie, wenn gezeichnet. Dieses Argument ist zur Kompatibilität mit dem seaborn-Paket verfügbar und wird für den allgemeinen Gebrauch nicht empfohlen. Stattdessen sollten Farben innerhalb von
scatter_kwsundline_kwsangegeben werden.Hinweis
Benutzer sollten diesen Parameter nicht angeben. Er ist nur für die Verwendung durch seaborn bestimmt, wenn es innerhalb eines
FacetGridarbeitet.label : string, optional
Ein direkt angegebener Legenden-Label für die Datenserie. Dieses Argument ist zur Kompatibilität mit dem seaborn-Paket verfügbar und wird für den allgemeinen Gebrauch nicht empfohlen. Stattdessen sollte das Label der Datenserie innerhalb von
scatter_kwsangegeben werden.Hinweis
Benutzer sollten diesen Parameter nicht angeben. Er ist nur für die Verwendung durch seaborn bestimmt, wenn es innerhalb eines
FacetGridarbeitet.Siehe auch
viz.plot_pos,viz.fit_line,numpy.polyfit,scipy.stats.probplot,scipy.stats.mstats.plotting_positionsBeispiele
Wahrscheinlichkeitsplot mit den Wahrscheinlichkeiten auf der y-Achse
>>> import numpy; numpy.random.seed(0) >>> from matplotlib import pyplot >>> from scipy import stats >>> from probscale.viz import probplot >>> data = numpy.random.normal(loc=5, scale=1.25, size=37) >>> fig = probplot(data, plottype='prob', probax='y', ... problabel='Non-exceedance probability', ... datalabel='Observed values', bestfit=True, ... line_kws=dict(linestyle='--', linewidth=2), ... scatter_kws=dict(marker='o', alpha=0.5))
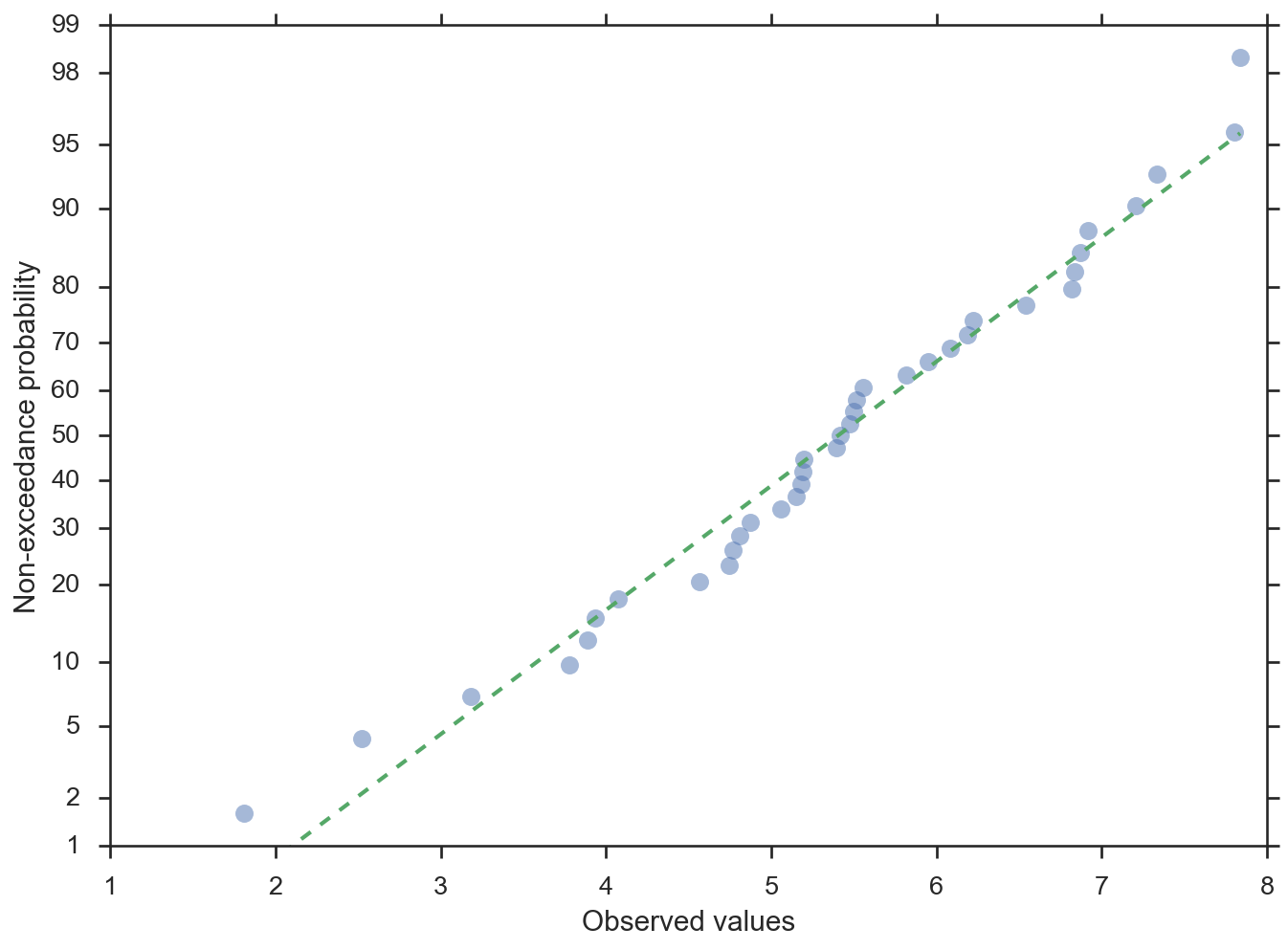
Quantilplot mit den Quantilen auf der x-Achse
>>> fig = probplot(data, plottype='qq', probax='x', ... problabel='Theoretical Quantiles', ... datalabel='Observed values', bestfit=True, ... line_kws=dict(linestyle='-', linewidth=2), ... scatter_kws=dict(marker='s', alpha=0.5))
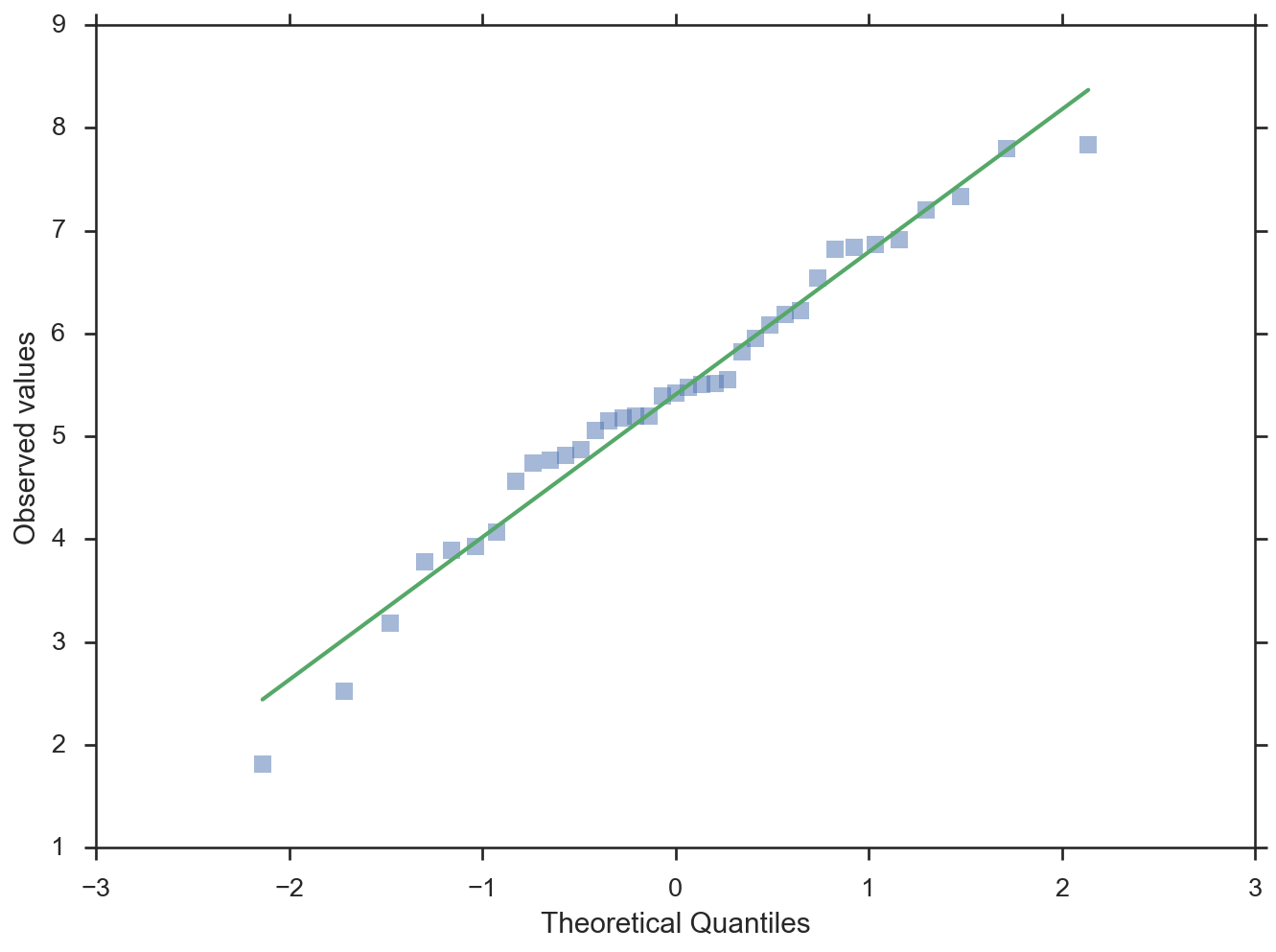
-
probscale.viz.plot_pos(data, postype=None, alpha=None, beta=None)[Quelle]¶ Berechnet die Plotting-Positionen für einen Datensatz. Leiht stark von
scipy.stats.mstats.plotting_positions.Eine Plotting-Position ist definiert als:
(i-alpha)/(n+1-alpha-beta)wobeiidie Rangordnung istndie Größe des Datensatzes istalphaundbetaParameter sind, die zur Anpassung der Positionen verwendet werden.
Die Werte von
alphaundbetakönnen explizit gesetzt werden. Typische Werte können auch über denpostypeParameter abgerufen werden. VerfügbarepostypeWerte (alpha, beta) sind- "type 4" (alpha=0, beta=1)
- Lineare Interpolation der empirischen CDF.
- "type 5" oder "hazen" (alpha=0.5, beta=0.5)
- Stückweise lineare Interpolation.
- "type 6" oder "weibull" (alpha=0, beta=0)
- Weibull-Plotting-Positionen. Unverzerrte Überschreitungswahrscheinlichkeit für alle Verteilungen. Empfohlen für hydrologische Anwendungen.
- "type 7" (alpha=1, beta=1)
- Die Standardwerte in R. Nicht empfohlen bei Wahrscheinlichkeitsskalen, da die minimalen und maximalen Datenpunkte Plotting-Positionen von 0 bzw. 1 erhalten und daher nicht angezeigt werden können.
- "type 8" (alpha=1/3, beta=1/3)
- Ungefähr median-unverzerrt.
- "type 9" oder "blom" (alpha=0.375, beta=0.375)
- Ungefähr unverzerrte Positionen, wenn die Daten normalverteilt sind.
- "median" (alpha=0.3175, beta=0.3175)
- Median-Überschreitungswahrscheinlichkeiten für alle Verteilungen (verwendet in
scipy.stats.probplot). - "apl" oder "pwm" (alpha=0.35, beta=0.35)
- Verwendet mit Wahrscheinlichkeits-gewichteten Momenten.
- "cunnane" (alpha=0.4, beta=0.4)
- Nahezu unverzerrte Quantile für normalverteilte Daten. Dies ist der Standardwert.
- "gringorten" (alpha=0.44, beta=0.44)
- Verwendet für Gumbel-Verteilungen.
Parameter data : array-ähnlich
Die Werte, deren Plotting-Positionen berechnet werden müssen.
postype : string, optional (Standard: "cunnane")
alpha, beta : float, optional
Benutzerdefinierte Parameter für die Plotting-Position, falls die über den postype Parameter verfügbaren Optionen nicht ausreichen.
Rückgabe plot_pos : numpy.array
Die berechneten Plotting-Positionen, sortiert.
data_sorted : numpy.array
Die ursprünglichen Datenwerte, sortiert.
Referenzen
http://artax.karlin.mff.cuni.cz/r-help/library/lmomco/html/pp.html http://astrostatistics.psu.edu/su07/R/html/stats/html/quantile.html https://docs.scipy.de/doc/scipy-0.17.0/reference/generated/scipy.stats.probplot.html https://docs.scipy.de/doc/scipy-0.17.0/reference/generated/scipy.stats.mstats.plotting_positions.html
-
probscale.viz.fit_line(x, y, xhat=None, fitprobs=None, fitlogs=None, dist=None, estimate_ci=False, niter=10000, alpha=0.05)[Quelle]¶ Passt eine Linie an x-y-Daten in verschiedenen Formen an (linear, log, prob-Skalen).
Parameter x, y : array-ähnlich
Unabhängige und abhängige Daten, bzw.
xhat : array-ähnlich, optional
Die Werte, bei denen
yhatgeschätzt werden soll. Wenn nicht angegeben, wird auf die sortierten Werte vonxzurückgegriffen.fitprobs, fitlogs : str, optional.
Definiert, wie die Daten transformiert werden sollen. Gültige Werte sind 'x', 'y' oder 'both'. Bei Verwendung von
fitprobssollten Variablen als Prozentsatz ausgedrückt werden, d. h. für eine Wahrscheinlichkeitstransformation werden die Daten mitlambda x: dist.ppf(x / 100.)transformiert. Für eine Log-Transformation mitlambda x: numpy.log(x). Achten Sie darauf, nicht denselben Wert fürfitlogsundfigprobsanzugeben, da beide Transformationen angewendet werden.dist : Verteilung, optional
Ein vollständig spezifiziertes scipy.stats-ähnliches Objekt, so dass
dist.ppfunddist.cdfaufgerufen werden können. Wenn nicht angegeben, wird standardmäßig eine minimale Implementierung vonscipt.stats.normverwendet.estimate_ci : bool, optional (False)
Schätzt und zeichnet ein Konfidenzband um die "Best-Fit"-Linie mittels eines Perzentil-Bootstraps.
niter : int, optional (Standard = 10000)
Anzahl der Bootstrap-Iterationen, wenn
estimate_ciangegeben ist.alpha : float, optional (Standard = 0.05)
Das Konfidenzniveau der Bootstrap-Schätzung.
Rückgabe xhat, yhat : numpy arrays
Lineare Modellschätzungen von
xundy.results : dict
Dictionary von linearen Fit-Ergebnissen. Schlüssel enthalten
- slope
- intersept
- yhat_lo (untere Konfidenzgrenze der geschätzten y-Werte)
- yhat_hi (obere Konfidenzgrenze der geschätzten y-Werte)